Knowing our DATA
We are told to execute the queries in the database right? And not pass on processing to the clients requesting the data?
THATS TRUE
However let's see an example of the opposite in action
It's important that we understand our data distribution
-
Which customer has the most rows in the main tables?
-
Which queries return many rows?
-
Etc...
This allows us to think outside the box and optimize, when we know our data we can bend the rules
HOW?
Let's see
Data Analysis
Start by examining the distribution of rows across your main tables. This can be done using simple SQL queries that count the number of rows for each customer or entity.
Enough banter, let's actually see how knowing our data allows us to improve a background job query
We use entity framework so here is the initial query. The query just gets a list of DISTINCT id's from a table
We also know that this jobs get executed frequently so it will NEVER return many rows, I did some digging and it returned a couple of rows each time it executed Remember the importance of knowing our workload and data
int[] resultArray = await (
from entity1 in UnitOfWork.Entity1Collection.All().Where(x => x.Property1 == maskedValue1)
join entity2 in UnitOfWork.Entity2Collection.All().Where(x => x.Property2 == null && DbFunctions.TruncateTime(x.Property3) <= DbFunctions.TruncateTime(maskedValue2))
on entity1.Id equals entity2.ForeignKey1
join entity3 in UnitOfWork.Entity3Collection.All() on entity2.ForeignKey2 equals entity3.Id
group entity1 by entity1.Id into groupedEntities
select groupedEntities.Key
).ToArrayAsync();
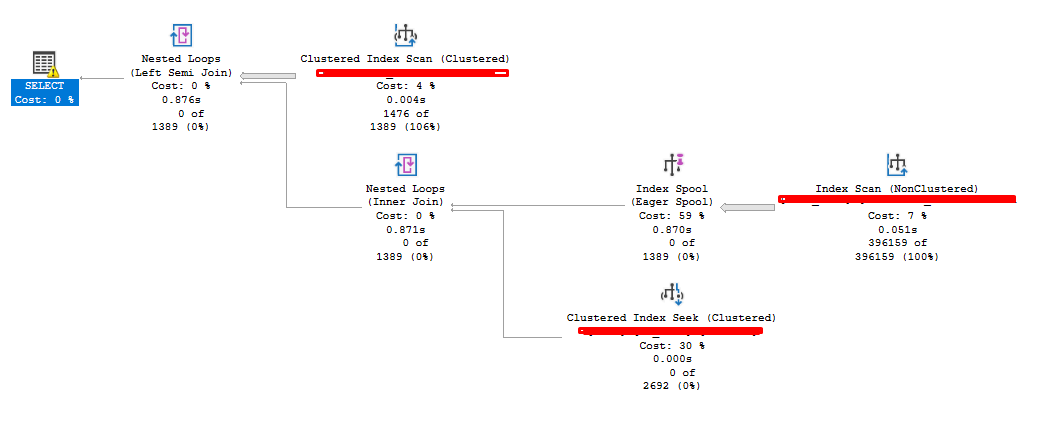
The execution plan
Anything suspicious? Here are the numbers Scan count 1476, logical reads 1191076
Don't get me wrong, the query is executed in a second, but why do a million reads?
The DISTINCT in the EF creates this index spool operator which is sort of a temp index used by the query,
What can we do about this? Again keep in mind that this query returns a couple of rows each time
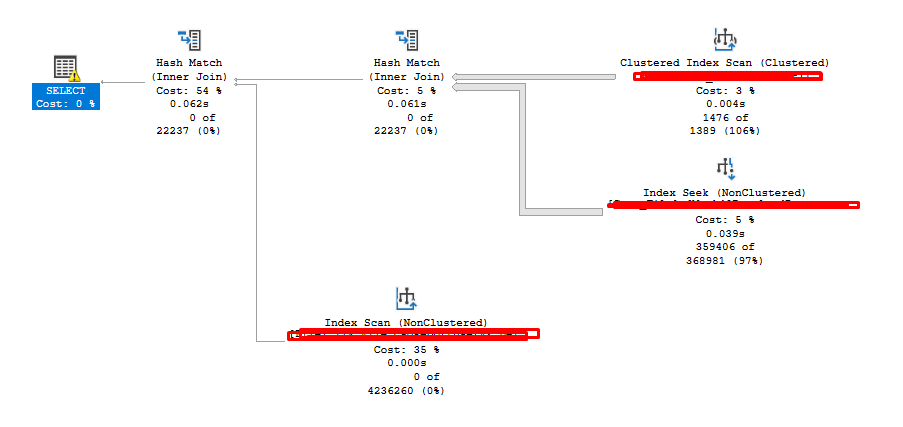
The same query plan WITHOUT the DISTINCT
int[] resultArray = await (
from entity1 in UnitOfWork.Entity1Collection.All().Where(x => x.Property1 == maskedValue1)
join entity2 in UnitOfWork.Entity2Collection.All().Where(x => x.Property2 == null && DbFunctions.TruncateTime(x.Property3) <= DbFunctions.TruncateTime(maskedValue2))
on entity1.Id equals entity2.ForeignKey1
join entity3 in UnitOfWork.Entity3Collection.All() on entity2.ForeignKey2 equals entity3.Id
select entity1.Id
).ToArrayAsync();
Scan count 2, logical reads 3280
I think this is a big different right?
Now the problem is we dont have the DISTINCTION so there is a RISK of getting duplicate data, BUT since we know our data we can be sure those duplicates will be around 5-10 Which means we can just filter them in our C# code easily, taking load of the database
And just a simple change optimized our code
So in summary
Know your data, that way you can break the rules
Know your workload, then you can manipulate the clients as processors and take load of the DB
In my humble experience, eager index spool has always been a red flag when I inspect queries